Latest posts for tag debtags
Fixed XSS issue on debtags.debian.org
Thanks to Moritz Naumann who found the issues and wrote a very useful report, I fixed a number of Cross Site Scripting vulnerabilities on https://debtags.debian.org.
The core of the issue was code like this in a Django view:
def pkginfo_view(request, name):
pkg = bmodels.Package.by_name(name)
if pkg is None:
return http.HttpResponseNotFound("Package %s was not found" % name)
# …
The default content-type of HttpResponseNotFound is text/html, and the
string passed is the raw HTML with clearly no escaping, so this allows
injection of arbitrary HTML/<script> code in the name variable.
I was so used to Django doing proper auto-escaping that I missed this place in which it can't do that.
There are various things that can be improved in that code.
One could introduce
escaping
(and while one's at it, migrate the old % to format):
from django.utils.html import escape
def pkginfo_view(request, name):
pkg = bmodels.Package.by_name(name)
if pkg is None:
return http.HttpResponseNotFound("Package {} was not found".format(escape(name)))
# …
Alternatively, set content_type
to text/plain:
def pkginfo_view(request, name):
pkg = bmodels.Package.by_name(name)
if pkg is None:
return http.HttpResponseNotFound("Package {} was not found".format(name), content_type="text/plain")
# …
Even better, raise Http404:
from django.utils.html import escape
def pkginfo_view(request, name):
pkg = bmodels.Package.by_name(name)
if pkg is None:
raise Http404(f"Package {name} was not found")
# …
Even better, use standard shortcuts and model functions if possible:
from django.shortcuts import get_object_or_404
def pkginfo_view(request, name):
pkg = get_object_or_404(bmodels.Package, name=name)
# …
And finally, though not security related, it's about time to switch to class-based views:
class PkgInfo(TemplateView):
template_name = "reports/package.html"
def get_context_data(self, **kw):
ctx = super().get_context_data(**kw)
ctx["pkg"] = get_object_or_404(bmodels.Package, name=self.kwargs["name"])
# …
return ctx
I proceeded with a review of the other Django sites I maintain in case I reproduced this mistake also there.
Evolution's old odd mail folders to mbox
Something wrong happened in my dad's Evolution. It just would get stuck checking mail forever, with no useful diagnostic that I could find. Fun. Not.
Anyway, I solved by resetting everything to factory defaults, moving away all gconf entries and .evolution/ files. Then it started to work again, of course then I needed to reconfigure it from scratch.
It turned out however that some old mail was only archived locally, and in a kind of weird format that looks like this:
$ ls -la Enrico/
total 336
drwx------ 2 enrico enrico 4096 Jul 23 03:05 .
drwxr-xr-x 7 enrico enrico 4096 Jul 23 03:12 ..
-rw------- 1 enrico enrico 3230 Dec 4 2010 113.HEADER
-rw------- 1 enrico enrico 14521 Dec 4 2010 113.TEXT
-rw------- 1 enrico enrico 3209 Oct 22 2010 134.HEADER
-rw------- 1 enrico enrico 2937 Oct 22 2010 134.TEXT
-rw------- 1 enrico enrico 3116 Jun 27 2011 15.
-rw------- 1 enrico enrico 3678 Jun 27 2011 168.
-rw------- 1 enrico enrico 73 Apr 27 2009 22.1.MIME
-rw------- 1 enrico enrico 3199 Apr 27 2009 22.2
-rw------- 1 enrico enrico 88 Apr 27 2009 22.2.MIME
[...]
I couldn't even find the name of that mail folder layout, let alone conversion tools. So I had to sit down and waste my sunday break writing software to convert that to a mbox file. Here's the tool, may it save you the awful time I had today: http://anonscm.debian.org/gitweb/?p=users/enrico/evo2mbox.git
Note: feel free to fork it, or send patches, but don't bother with feature requests. Evolution isn't and won't be a personal interest of mine. Anything that makes an afternoon at my parents more tiresome than a whole busy month of paid work, doesn't deserve to be.
Luckily they now seem to have changed the local folder format to Maildir.
Giving away distromatch
at last year's Fosdem I [[tried to inject a lot of energy into distromatch|talks/20120204-Fosdem]] but shortly afterwards I've had to urgently rewrite the nm.debian.org website.
After Lars Wirzenius GTDFH talks in Bologna and Varese I wrote a tool which, among other things, is able to scan my home dir and list how many projects I'm working on.
The output was scary. Like, they are too many. Like, I couldn't even recite the list out of memory. And since I couldn't do that, I had no idea there were so many. And I kept being stressful because I couldn't manage to take care of them all properly.
Now that I became conscious of the situation, it's time to deal with it like a grown up, and politely back off from some of my irresponsible responsibilities.
Distromatch is one of them. It had just [[started as a proof of concept prototype|2011/debian/distromatch]], and I had the vision that it could be the basis for a fantastic culture of sharing and exchange of information across distributions.
I need to distinguish the vision from the responsibility. I still have that vision for distromatch, but I cannot take responsibility for making it happen.
So I am giving it up to anyone who has the time and resources to pick up that responsibility.
Current status
It works well enough as a prototype. I believe it can successfully map a large enough slice of packages, that one can prototype stuff based on it.
I have for example used it to export the Debtags categories for other distros, and the resulting file looked big enough to be used for prototyping category-based features on distributions that don't have them yet.
I think it also works well enough to support a few common use cases, like sharing screenshots, or doing most of the work of converting dependency lists from a distro to another.
And finally, anyone can deploy it, and work on it.
Existing data sources
Everything I index in the Debian distromatch deployment is available at http://dde.debian.net/exports/distromatch/. The rpm-based data in there comes from an export script I wrote that runs on Sophie, but which I cannot maintain properly.
This is an experimental export of Fedora and OpenSUSE data: http://tmp.vuntz.net/misc/distromatch/distromatch-opensuse-fedora.tar
All existing export scripts are found in distromatch git repo on gitorious.
Contacts I gathered at Fosdem
At Fosdem I devoted quite some work to get contacts from all possible distributions and software repositories, so that distromatch could be hooked into them. Here is a dump of what I have collected:
- Debian: me
- OpenSuse: Vincent Untz and Adrian Schröter
- Fedora: Tom "Spot" Callaway
- Arch: Tasser on IRC
- CPAN: contact the people of https://metacpan.org/, on
irc.perl.org:#metacpanor make an issue on github - NetBSD: ask on
#netbsdon Freenode - FreeBSD: Baptiste Daroussin (bapt)
- Mageia: Olivier Thauvin
Some of those contacts may have "expired" in the meantime: I wouldn't assume all of them still remember talking with me, although most probably still do.
My commitment for the time being
I am happy to commit, at the moment, to maintaining a working data export for Debian data. I can take responsibility for making it so that the Debian data for it stays up to date, and to fix it asap if it isn't the case.
I hope that now someone can take distromatch over from me, and make it grow to achieve its great potential.
More diversity in Debian skills
This blog post has been co-authored with Francesca Ciceri.
In his Debconf talk, zack said:
We need to understand how to invite people with different backgrounds than packaging to join the Debian project [...] I don't know what exactly, but we need to do more to attract those kinds of people.
Francesca and I know what we could do: make other kinds of contributions visible.
Basically, we should track and acknowledge the contributions of webmasters, translators, programmers, sysadmins, event organisers, and so on, at the same level as what we do for packagers: DDPO, minechangelogs, Portfolio...
For any non-packaging activity that we can make visible and credited, we get:
-
to acknowledge the people who do it, and show that they are active contributors in the project;
-
to acknowledge the work that gets done, and show the actual amount of non-packaging work that gets done in Debian every day;
-
to allow non-packagers to have a reputation, too: first of all, they deserve it, and among other things, it would make nm processing trivial.
Here's an example: who's the lead translator for German? And if you are German, who's the lead translator for Spanish? Czech? Thai? I (Enrico) don't know the answers, not even for Italian, but we all should! Or at least it should be trivial to find out.
To start to change this, is just a matter of programming.
Francesca already worked on a list of trackable data sources, at least for translators.
Here are some more details, related to translation:
-
Translations can be tracked via the i18n robot (and relative statistics). This works only with teams who activated the robot and actively use the pseudo-urls in their messages on localisation mailing lists. Some translators don't bother to do it but it's ok to only support the main workflow. It beats extracting .po files from
l10n-tagged BTS bugs at any rate. -
DPN and website translations: for wml pages there's a specific field to be extracted for each translated page: grep for
maintainer="name"on normal wml pages, while for DPN translations we have a specifictranslator="name"field. The problem is that this field is not mandatory, so sometimes there's no indication of the maintainer. Again, it's ok to only support the main workflow.Anyway, this is preferable to the cvs log: often the commit is done by the coordinator of the team and not by the actual translator. See above for the alternative solution of using the statistics provided by the i18n bot.
-
DDTSS: since the new release of DDTSS-Django, done by Martijn van Oosterhout about a year ago, the contributions are by default non-anonymous. This should be easy to track.
-
http://wiki.debian.org: it is more complicated because in the wiki we do not have a proper l10n translation workflow, so the only thing that can be tracked are changelogs
$LANG/*pages. A nice idea would be to have translated pages list the version of the page that was translated and who did the translation. -
translation of debian manuals and release notes: usually in the translation of manuals and long documentation there is a specific translator field.
And here are some notes about other fields:
-
DPN editors: for each issue there's a list of editors at the bottom of the page. In the wml: grep for
editor=. -
Artwork: artwork submitted via debianart are easy to track on the portal. Anyway usually you can find the author in the license and copyright file.
-
Programming: the only thing we have is the list of services which can be expanded if needed.
-
Press and publicity: there seems to be not much besides svn logs.
-
l10n-english: The Smith Review Project page has some tracking links. Other activities can probably only be tracked, at the moment, via mailing list activity.
-
Events: we can use the "main coordinator" field on
www.debian.org/events/$year/$date-$eventname.wml: grep for<define-tag coord>; for events not published on the http://www.debian.org, but only on http://wiki.debian.org, the coordinator or the contact for the event is usually present on the page itself. -
Sysadmins: we haven't asked DSA.
And finally, if you are still wondering who those translation coordinators are, they are listed here, although not all teams keep that page up to date.
Of course, when a data source is too hard to mine, it can make sense to see if the workflow could be improved, rather than spending months writing compicated mining code.
This is a fun project for people at Debconf to get together and try.
If by the end of the conference we had a way to credit some group of non-packaging contributors, even if just one like translators or website contributors, at least we would finally have started having official trackers for the activities of non-packagers.
Debtags for derivative distributions
Sometimes I do cool stuff and I forget to announce it.
Ok, so I recently announced a new Debtags website.
I forgot to say in the announcement that the new website does not only know of Debian packages: see for example this page, at the very bottom it says: "Distributions: oneiric, precise, sid, testing".
This means that already, here and now, debtags.debian.net can be used to tag packages from both Debian and Ubuntu, and can easily be extended to cover the entire Debian ecosystem.
If you are a package maintainer, you will notice that your maintainer page shows your packages from everywhere. If you want to filter things a bit, for example hide obsolete packages from an old Debian Stable or Ubuntu LTS, just click on the "Settings" link on the top right to configure the page.
How it works
The magic is in this mergepackages script, which is run daily, and exports merged Packages files at dde.debian.net. The debtags.debian.net concept of Packages and Sources files are just those all-merged.gz and all-merged-sources.gz.
The merging is simple: that rebuild script processes files in order, and the first version of a package that is found is chosen as the base for the one that will go in the merged Packages file. Some fields like "Description" are just taken from this pivot package, others like Architecture or dependencies are merged into it. It's arbitrary, but works for me: the result has all the packages with all their possible architectures and dependencies, and is ready to be indexed with apt-xapian-index.
At the moment I pull data from Debian and Ubuntu, but you can see that the script can easily be extended to pull data from any Debian-style ftp archive, so any Debian derivative can go in. I've already started negotiations with the Derivatives Census on how to add any Debian derivative and keep the list up to date.
How to export tags for your own distribution
I'll use Ubuntu as an example since the data is already available.
The way you add Debtags to the Ubuntu packages file is just this one:
- Get the full reviewed tag database
- Optionally filter out those packages that you are not interested in
- Tweak this script to build an overrides file.
- Give the overrides file to your favourite ftp archive building tool.
The make-overrides is a bit rusty: if you improve it, please send me your
changes.
That is it, nothing else required, no excuses, it's ready, here, now!
Hitches and gotchas
This merged Packages file is a bit of a hack, and suffers from name conflicts across distributions, where two different softwares are packaged in two different distributions with the same name.
Ideally, name conflicts should not happen: if a derivative decided to package
kate and call it gedit, they deserve to have it tagged uitoolkit::gtk.
I think it's rather important that the whole Debian ecosystem works as much as
possible with a single package namespace.
However, that reasoning fails if you take time into account: packages get
renamed, like git and chromium, and may mean completely different things,
for example, if you compare Debian Stable with Debian Sid.
This last is a problem caused by debtags only working with package names but not package versions. I have a strategy in mind based on being able to override the stable tag database using headers in debian/control; it still needs some details sorted out, but I'm confident we will be able to address these issues properly soon enough.
Why stop at the Debian ecosystem?
Why indeed. I'm clearly trying to use FOSDEM, and the CrossDistribution devroom as the venue to discuss just that.
Deploying distromatch
I have been working on allowing anyone to set up their own distromatch instance.
For Debian and Ubuntu, I can easily generate the distromatch input using UDD and the Contents files found in any mirrors.
For the whole RPM world, thanks to Olivier Thauvin I have been able to set up regular exports from the vast Sophie database.
I have set up distromatch access on DDE, which can also serve as a list of all working distributions so far. If you have access to the full dataset of package names and package contents for a distribution not in that list, please get in touch and we can add it.
I'm also exporting the full raw dataset which enables anyone to set up the same distromatch environment on their own machines.
Here is how:
# Get distromatch
git clone git://gitorious.org/appstream/distromatch.git
cd distromatch
# Fetch distribution information (updated every 2 days)
wget http://dde.debian.net/exports/distromatch-all.tar.gz
# Unpack it
mkdir data
tar -C data -zxf distromatch-all.tar.gz
# Reindex it (use --verbose if you are curious)
./distromatch --datadir=data --reindex --verbose
# Run it
./distromatch --datadir=data debian gedit
What does this mean? For example it means that if another distribution has some data (categories, screenshots...) that your distribution doesn't have, you can use distromatch to translate package names, then go and get it!
My next step is going to be to improve the distromatch functionality in DDE and possibly build a simple user friendly web interface to it. If you have some JQuery experience and would like to help, don't wait to get in touch.
update-apt-xapian-index on other distros
I've drafted a little HOWTO on using apt-xapian-index on non-Debian distributions.
The procedure has been tried on Mageia with some success, and there's no reason it wouldn't work everywhere else: the index itself does not depend on anything distro-specific.
Match package names across distributions
What would happen if we had a quick and reliable way to match package names across distributions?
These ideas came up at the appinstaller2011 meeting:
- it would be easy to lookup screenshots in the local distro, and if there are none then fall back on other distributions;
- it would be easy to port Debtags to other distributions, and possibly get changes back;
- it would be trivial to add a
[patches in $DISTRO]link to the PTS - it would be easy to point to other BTSes
We thought they were good ideas, so we started hacking.
To try it, you need to get the code and build the index first:
git clone git://git.debian.org/users/enrico/distromatch.git
cd distromatch
# Careful: 90Mb
wget http://people.debian.org/~enrico/dist-info.tar.gz
tar zxf dist-info.tar.gz
# Takes a long time to do the indexing
./distromatch --reindex --verbose
Then you can query it this way:
./distromatch $DISTRO $PKGNAME [$PKGNAME1 ...]
This would give you, for the package $PKGNAME in $DISTRO, the corresponding package names in all other distros for which we have data. If you do not provide package names, it automatically shows output for all packages in $DISTRO.
For example:
$ time ./distromatch debian libdigest-sha1-perl
debian:libdigest-sha1-perl fedora:perl-Digest-SHA1
debian:libdigest-sha1-perl mandriva:perl-Digest-SHA1
debian:libdigest-sha1-perl suse:perl-Digest-SHA1
real 0m0.073s
user 0m0.056s
sys 0m0.016s
Yes it's quick. It builds a Xapian index with the information it needs, and then it reuses it. As soon as I find a moment, I intend to deploy an instance of it on DDE.
It is using a range of different heuristics:
- match packages by name;
- match packages by desktop files contained within;
- match packages by pkg-config metadata files contained within;
- match packages by [/usr]/bin/* files contained within;
- match packages by shared library files contained within;
- match packages by devel library files contained within;
- match packages by man pages contained within;
- match stemmed form of development library package names;
- match stemmed form of shared library package names;
- match stemmed form of perl library package names;
- match stemmed form of python library package names.
This list may get obsolete soon as more heuristics get implemented.
Euristics will never cover all corner cases we surely have, but the idea is that if we can match a sizable amout of packages, the rest can be somehow fixed by hand as needed.
The data it requires for a distribution should be rather straightforward to generate:
- a file which maps binary package names to source package names
- a file with the list of files in all the packages
For example:
$ ls -l dist-debian/
total 39688
-rw-r--r-- 1 enrico enrico 1688249 Jan 20 17:37 binsrc
drwxr-xr-x 2 enrico enrico 4096 Jan 21 19:12 db
-rw-r--r-- 1 enrico enrico 29960406 Jan 21 10:02 files.gz
-rw-r--r-- 1 enrico enrico 8914771 Jan 21 18:39 interesting-files
$ head dist-debian/binsrc
openoffice.org-dev openoffice.org
ext4-modules-2.6.32-5-4kc-malta-di linux-kernel-di-mipsel-2.6
linux-headers-2.6.30-2-common linux-2.6
libnspr4 nspr
ipfm ipfm
libforks-perl libforks-perl
med-physics debian-med
libntfs-3g-dev ntfs-3g
libguppi16 guppi
selinux selinux
$ zcat dist-debian/files.gz | head
memstat etc/memstat.conf
memstat usr/bin/memstat
memstat usr/share/doc/memstat/changelog.gz
memstat usr/share/doc/memstat/copyright
memstat usr/share/doc/memstat/memstat-tutorial.txt.gz
memstat usr/share/man/man1/memstat.1.gz
libdirectfb-dev usr/bin/directfb-config
libdirectfb-dev usr/bin/directfb-csource
libdirectfb-dev usr/include/directfb-internal/core/clipboard.h
libdirectfb-dev usr/include/directfb-internal/core/colorhash.h
interesting-files and db are generated when indexing.
To prove the usefulness of the idea (but does it need proving?), you can find in the same git repo a little example app (it took me 10 minutes to write it), that uses the distromatch engine to export Debtags tags to other distributions:
$ ./exportdebtags fedora | head
memstat: admin::benchmarking, interface::commandline, role::program, use::monitor
libdirectfb-dev: devel::lang:c, devel::library, implemented-in::c, interface::framebuffer, role::devel-lib
libkonqsidebarplugin4a: implemented-in::c++, role::shared-lib, suite::kde, uitoolkit::qt
libemail-simple-perl: devel::lang:perl, devel::library, implemented-in::perl, role::devel-lib, role::shared-lib, works-with::mail
libpoe-component-pluggable-perl: devel::lang:perl, devel::library, implemented-in::perl, role::shared-lib
manpages-ja: culture::japanese, made-of::man, role::documentation
libhippocanvas-dev: devel::library, qa::low-popcon, role::devel-lib
libexpat-ocaml-dev: devel::lang:ocaml, devel::library, implemented-in::c, implemented-in::ocaml, role::devel-lib, works-with-format::xml
libgnutls-dev: devel::library, role::devel-lib, suite::gnu
Just in case this made you itch to play with Debtags in a non-Debian distribution, I've generated the full datasets for Fedora, Mandriva and OpenSUSE.
Others have been working on the same matching problem. After we started writing code we started to become aware of existing work:
- whohas
- PackageMap
- Equivalent-Packages, statistically generated from package contents, more info in this post
I'd like to make use of those efforts, maybe to cross-validate results, maybe even better as yet another heuristics.
Update:
I built a simple distromatch query system into DDE!
A prototype webby markety appy thing
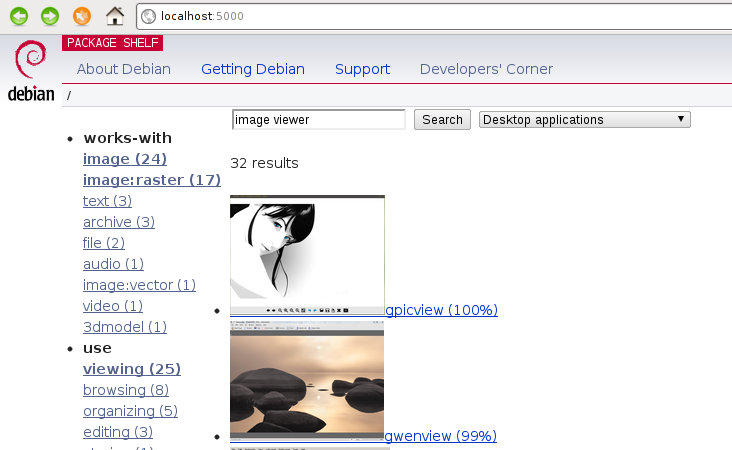
What better way to introduce my work at an Application Installer meeting than to come with a prototype package browser modeled after shopping sites developed in just a few hours?
It's a little Flask webapp that just works on any Debian system, using the local apt-xapian-index as a backend. It has fast keyword search, faceted navigation and screenshots, and it runs on your system showing the packages that you have available.
To try it:
git clone git://git.debian.org/users/enrico/pkgshelf.git
cd pkgshelf
./web-server.py
Then visit http://localhost:5000
It didn't have much interface polishing, as it's just a quick technology demo. However you can see that:
- keyword search is fast (fast enought that it could be made to search as you type);
- relevant tags appear on the left, grouped by facets;
- the most relevant tags are highlighted;
- the less relevant tags could be hidden behind a
[more]expander; - you can choose several strategies to hide packages you may find irrelevant.
Things that need doing:
- hiding uninteresting facets;
- making it pretty.
It's essentially JavaScript and CSS work. Anyone wants to play?
Cross-distro Meeting on Application Installer
I have been to a Cross-distro Meeting on Application Installer which to the best of our knowledge is also the first one of its kind. Credit goes to Vincent Untz for organising it, to OpenSUSE for hosting it and to the various sponsors for getting us there.
It went surprisingly well. We got along, got stuff done, did as much work as possible to agree on as many formats, protocols and technologies as we possibly could.
The timing of it is very important, as most major distros would like to adopt some of the features that just became popular in the various new app markets and stores, such as screenshots, user comments and ratings. It looks like a lot of new code is about to be written, or a lot of existing code is about to gain quite a bit of popularity.
For my part, I presented the work on Debtags and apt-xapian-index.
With regards to Debtags, other distros seem to be missing a compehensive classification system, and Debtags is, well, it.
With regards to apt-xapian-index, we just noticed that it's the perfect back-end for what everyone would like to do, and the index structure is rather distribution-agnostic, and it's been road-tested with considerable success by at least software-center, so it attracted quite a bit of interest, and will likely attract some more.
Just to prove a point I put together [[a prototype webby markety appy thing|pkgshelf]] in just a few hours of work.
The meeting was also the ideal place to create a joint effort to [[match package names across distributions|distromatch]], which means that a lot of things that were hard to share before, such as screenshots, tags and patches, are suddenly not hard to share anymore.